Docker Installation Guide¶
Docker is now firmly placed among the most important tools for a data science team. It is an open-source application that performs operating-system level containerization. These containers can hold multiple independently running applications. Docker creates a portable and reusable environment and it is far easier then running explicit servers or virtual environments. In data science today, Docker is the industry standard for containerization of machine learning models and AI services.
The community package of the Docker Engine is called docker-ce. Fundamentally, a docker container can be thought
of as a running script with all the necessary components bundled within. The containers themselves sit on top of an
operating system as shown in the following diagram.
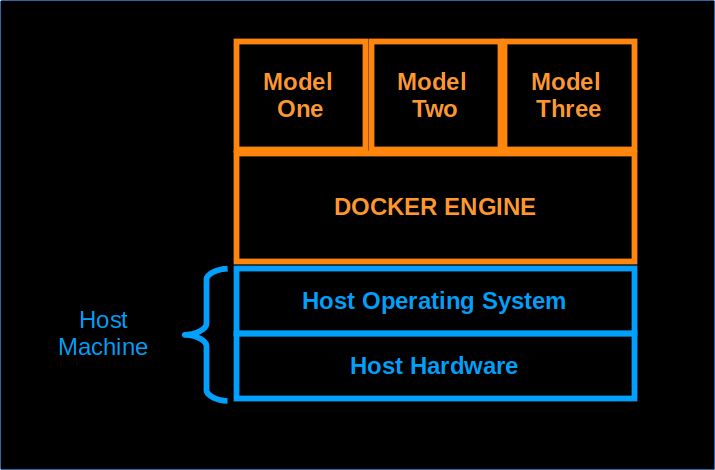
The Docker container is a running process that is kept isolated from the host and from other containers. One of the important consequences of this isolation is that each container interacts with its own private filesystem. A Docker image includes everything needed to run an application: code, runtime libraries, and a private filesystem.
Docker installation and setup¶
To install the Docker Engine use the appropriate guide from the following:
When you have finished the install you should be able to run the “hello world” example. To install it, perform the following steps:
~$ docker run hello-world
or if root privileges are required
~$ sudo docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
Congratulations! You have just run a container. It could have been anything from a fully functional spark environment to a simple model that a colleague has recently deployed. There are a number of arguments for the docker run command that we will get into, but this is the basis for running containers.
NVIDIA Docker¶
Important
This section on NVIDIA Docker is here for your reference, but it is not required for Galvanize trainings
To use TensorFlow with a GPU you need to ensure that the
NVIDIA driver, CUDA, and
additional required libraries are set up and versioned appropriately. Then you can install tensorflow-gpu. There is
some amount of overhead involved in getting this ecosystem running smoothly. Additionally, there are maintenance
requirements as the stable version changes over time. TensorFlow can also be installed via Docker with the use of a GPU.
The process is similar for PyTorch, Caffe, and (in general) any deep-learning framework that makes use of GPUs. The NVIDIA container toolkit, or simply nvidia-docker, is an incredibly convenient way to build and run GPU-accelerated Docker containers. Once this is done, you can pull down the latest GPU version of tensorflow (with Jupyter support) by doing this:
~$ docker pull tensorflow/tensorflow:latest-gpu-jupyter
NVIDIA Docker and GPU computing are not required for this course or any in this specialization, but
knowledge of Dockerized versions of TensorFlow and similar tools can save significant amounts of time (you will need
to ensure that docker-ce is installed).